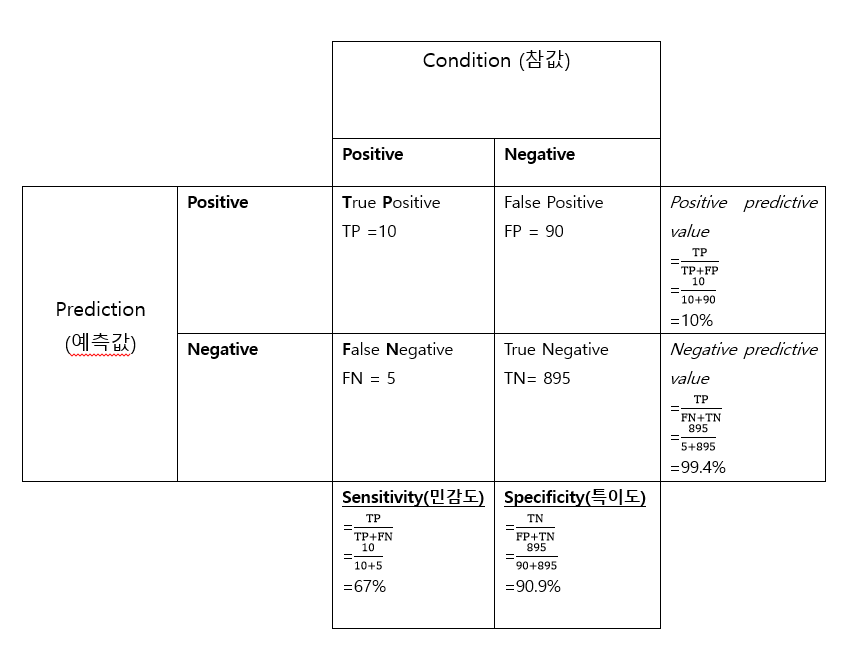
1. 정분류율(Accurcy)
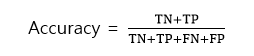
-전체중에서 맞게 예측한것의 비율
2. 오분류율(Error Rate)
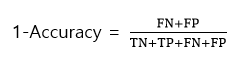
-전체중에서 잘못예측한 것의 비율
3. 특이도(Specificity)
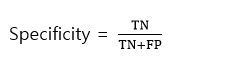
-실제 Negative 중에서 Negative로 잘 예측한 비율.
4. 민감도(Sensitivity)

-실제 Positive 중에서 Positive로 잘 예측한 비율.
5. 정확도(Precision)
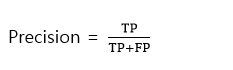
-예측된 Positive 중에서 Positive로 잘 예측한 비율.
(Positive로 예측된 것 중에서 실제 Positive인 비율)
6. 재현율(Recall) : 민감도와 같다.

7. F1 score
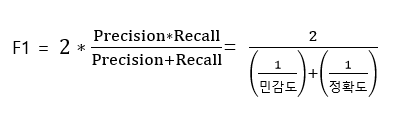
#뒤에 붙는 P, N은 예측 기준이다.
앞에 붙는 T,F 는 잘 예측했느냐(맞췄냐 틀렸냐)를 나타낸다.
TP : P로 잘 예측한것 -> 참값은 P
FP : P로 잘못 예측한것(틀린것) -> 즉 참값은 N
FN: N으로 잘못 예측한것(틀린것) -> 즉 참값은 P
TN: N으로 잘 예측한것 ->참값은 N
#좋은 모형을 판단하는 기준은?
정분류율, 민감도, 특이도가 모두 좋아야 한다.
#만약 정분류율으로만 모형을 판단한다면?
-이 예제의 경우 참 값은 Positive : 15, Negative : 985 이다.
이 경우, 예측을 모두 Negative로 하면 정분류율은 985/1000 = 98.5%로 매우 높게 나온다.
하지만 민감도TP/(TP+FN) = 0, 특이도TN/(FP+TN) = 100 으로 ,
사실은 매우 안좋은 모형인 것이다.
| TP (0) | FP(0) |
| FN(15) | TN(985) |
#여기서 햇갈릴 수 있는 것 : 민감도 와 정확도
민감도 :

정확도:
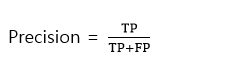
위 예제에서 참 값은 Positive : 15, Negative : 985 이다.
이번에는 1000명을 모두 Positive로 예측했다고 생각해보고 둘을 비교해본다.
| TP (15) | FP(985) |
| FN(0) | TN(0) |
민감도 = 15/(15+0) = 100% ( 실제 Positive 중에서, Positive로 맞게 예측한 비율)
정확도 = 15/(15+985) = 0.15% (예측된 Positive중에서 , Positve로 맞게 예측한 비율,
Positive로 예측된 것 중에서 실제 Positive인 비율)
'R프로그래밍,통계학' 카테고리의 다른 글
| 분류모형2-2 분류모형의 평가- 리프트도표/Gain chart (0) | 2020.09.22 |
|---|---|
| 분류모형2-1 분류모형의 평가- ROC커브 (0) | 2020.09.21 |
| 텍스트 처리 함수 1-1)기본함수 기초(in R) (0) | 2020.09.14 |
| 비정형 데이터분석_정규표현식(in R) (0) | 2020.09.13 |
| Melt() 와 Cast()함수 (0) | 2020.09.02 |


